Did you know in 2.17mins you can discover your present heart condition?

Photo by Kenny Eliason on Unsplash
I think you’ll agree with me when I say:
Artificial Intelligence is the future of computing.
The study of AI has improved over the years with multiple universities teaching the fundamentals and transcending verbal courses to real life sectors with the health sector being one of the foremost benefactor. Artificial intelligence in the health sector is gradually taking the world by surprise.
From a history of the earliest notable work in AI by Alan Mathison Turing in the mid-20th century, now, we have over 400% increase in student study on AI according to Will Hazell an education correspondent in 2021.
From where I stand, AI has never been more useful than it is right now and a handful of well oriented organisations are tilting towards this light, undoubtedly, Artificial Intelligence is the future and would definitely cause a change to human life as well as cut across several sectors of human endeavour.
The purpose of this article is to introduce you to the J-Predict System.
So what does this mean and what it does for you? The J-predict system is a heart disease prediction system that denotes a result based on inputs in respect to defined columns which in turn means from your comfort you can discover your present heart condition. How amazing!
HOW THIS PROGRAM WAS DEVELOPED?
Below is the thorough break down of this program development using decision tree and logistic regression algorithms
Importing necessary Libraries

importing the dependencies
Metrics for classification technique, scaler and model building

importing the dependencies
DATA LOADING
Here we will be using the pandas read_csv function to read the dataset. Specify the location of the dataset and import them.

Load data

checking the first five rows
DECISION TREE
EXPLORATORY DATA ANALYSIS

this is the shape of the dataset
Reasoning: We have a dataset with 303 rows which indicates a smaller set of data.
As above we saw the size of our dataset now let’s see the type of each feature that our dataset holds.
Resoning: We have a dataset with 303 rows which indicates a smaller set of data.
We have 13 of 14 features as integers and a single coloumn float data type and there isn’t a missing value
Let’s view how the data is spread to gather more insight

giving more information on dataset
Let’s go deeper and find out if there are null values in our dataset and output the value count for the target column
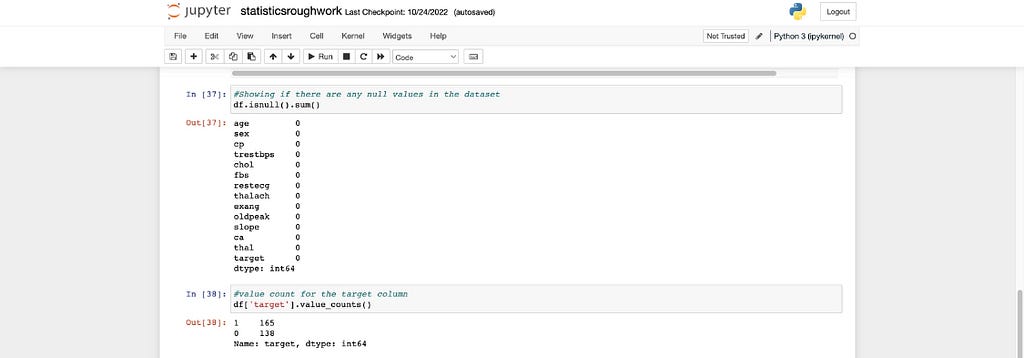
finding for null values
Modelling (Splitting our dataset)

Splitting the dataset
ACCURACY SCORE
We need to test and train this data to be certain of it’s quality, reliability and meticulousness.

finding the program’s accuracy score
THE PREDICTIVE SYSTEM
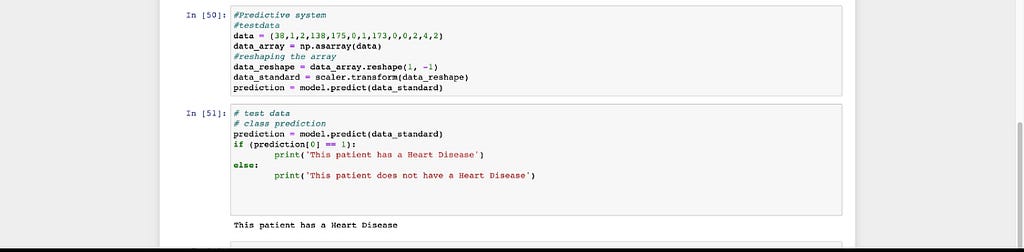
the predictive system
Note: for the view of Logistic Regression algorithm visit my GitHub
HOW TO USE?
The J-Predict heart condition system is an easy to understand program which has a user GUI wherein inputs are given, received, processed, predicted and also outputs a meticulous result. Below is a tutorial guide on how the program operates:
https://medium.com/media/baa861981f1d423d0194a0e74e6191fd/href
HOW THE PROGRAM WORKS?

Photo by Kanayo Justice on figma
It’s essential that we understand the work flow of this program, how it works, relates and gives us results, this would aid us and give us more insight and depth into it’s operations.
First, we received a .csv set of historical data and it is passed through a testing and training phase, then when made successful predicts an outcome and gives a result.

photo by Kanayo Justice on figma
HOW ACCURATE IS THIS PROGRAM?

Photo by Kanayo Justice on figma
This program was critically analysed and passed through the decision tree algorithm and the logistic regression algorithm for the best approach structure to giving the most meticulous results.
On accounts of both algorithms, the decision tree after the training and testing phase gives the percentage of accuracy: 88%, 75% respectively whilst the logistic regression algorithm gives the percentage of accuracy: 86%, 85% respectively. Hence, regarding this set of historical data for prediction the _l_ogistic regression algorithm is a much more fit suite to deduce accurate results.
CONCLUSION ON HEART DISEASE PREDICTION
1. We did data visualization and data analysis of the target variable, age features, and what not along with its univariate analysis and bivariate analysis.
2. We also did a complete feature engineering part in this article which summons all the valid steps needed for further steps i.e model building.
3. From the above model accuracy, Decision tree is giving us train and test accuracy which is 88%, 75% and Logistic regression is giving us train and test accuracy which is 86%, 85%. From this accuracy score it is safe to use Logistic Regression on this data set because it has a higher accuracy score.
END NOTES
Remeber, this project has been made open source.
Here’s the repo link to this article. Hope you liked my article on Heart disease detection using Decision tree and Logistic Regression algorithms. If you have any opinions or questions, then comment below.
Read on AV Blog about various predictions using Decision trees.
ABOUT ME
Greetings to everyone, I’m currently studying in Birmingham City University as an Msc Artificial Intelligence student. I’ve got an immense interest in this field, i.e. Data Science, along with its other subsets of Artificial Intelligence such as Computer Vision, Machine Learning, and Deep learning; feel free to collaborate with me on any project on the domains mentioned above (LinkedIn).
Hope you liked my article on Heart Disease Prediction? You can access my other articles, which are published on medium.